这篇文章主要讲解了“Java分布式一致性协议与Paxos,Raft算法是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Java分布式一致性协议与Paxos,Raft算法是什么”吧!

由于BASE理论需要在一致性和可用性方面做出权衡,因此涌现了很多关于一致性的算法和协议。其中比较著名的有二阶提交协议(2 Phase Commitment Protocol),三阶提交协议(3 Phase Commitment Protocol)和Paxos算法。
本文要介绍的2PC协议,分为两个阶段提交一个事务。并通过协调者和各个参与者的配合,实现分布式一致性。
两个阶段事务提交协议,由协调者和参与者共同完成。
角色 XA概念 作用
协调者 事务管理器 协调各个参与者,对分布式事务进行提交或回滚
参与者 资源管理器 分布式集群中的节点
分布式事务是指会涉及到操作多个数据库的事务,其实就是将对同一库事务的概念扩大到了对多个库的事务。目的是为了保证分布式系统中的数据一致性。
分布式事务处理的关键是:
需要记录事务在任何节点所做的所有动作;
事务进行的所有操作要么全部提交,要么全部回滚。
2.1. XA规范的组成
XA规范是由 X/Open组织(即现在的 Open Group )定义的分布式事务处理模型。 X/Open DTP 模型( 1994 )包括:
应用程序( AP )
事务管理器( TM ):交易中间件等
资源管理器( RM ):关系型数据库等
通信资源管理器( CRM ):消息中间件等
2.2. XA规范的定义
XA规范定义了交易中间件与数据库之间的接口规范(即接口函数),交易中间件用它来通知数据库事务的开始、结束以及提交、回滚等。而XA接口函数由数据库厂商提供。
二阶提交协议和三阶提交协议就是基于XA规范提出的其中,二阶段提交就是实现XA分布式事务的关键。
2.3. XA规范编程规范
配置TM,给TM注册RM作为数据源。其中,一个TM可以注册多个RM。
AP向TM发起一个全局事务。这时,TM会发送一个XID(全局事务ID)通知各个RM。
AP从TM获取资源管理器的代理(例如:使用JTA接口,从TM管理的上下文中,获取出这个TM所管理的RM的JDBC连接或JMS连接)。
AP通过从TM中获取的连接,间接操作RM进行业务操作。TM在每次AP操作时把XID传递给RM,RM正是通过这个XID关联来操作和事务的关系的。
AP结束全局事务时,TM会通知RM全局事务结束。开始二段提交,也就是prepare - commit的过程。
XA规范的流程,大致如图所示:
3.1. 二阶段提交的定义
二阶段提交的算法思路可以概括为:每个参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报,决定各参与者是否要提交操作还是中止操作。
所谓的两个阶段分别是:
第一阶段:准备阶段(投票阶段)
第二阶段:提交阶段(执行阶段)
3.1.1. 准备阶段
准备阶段分为三个步骤:
a. 事务询问
协调者向所有的参与者询问,是否准备好了执行事务,并开始等待各参与者的响应。
b. 执行事务
各参与者节点执行事务操作。如果本地事务成功,将Undo和Redo信息记入事务日志中,但不提交;否则,直接返回失败,退出执行。
c. 各参与者向协调者反馈事务询问的响应
如果参与者成功执行了事务操作,那么就反馈给协调者 Yes响应,表示事务可以执行提交;如果参与者没有成功执行事务,就返回No给协调者,表示事务不可以执行提交。
3.1.2. 提交阶段
在提交阶段中,会根据准备阶段的投票结果执行2种操作:执行事务提交,中断事务。
提交事务过程如下:
a. 发送提交请求
协调者向所有参与者发出commit请求。
b. 事务提交
参与者收到commit请求后,会正式执行事务提交操作,并在完成提交之后,释放整个事务执行期间占用的事务资源。
c. 反馈事务提交结果
参与者在完成事务提交之后,向协调者发送Ack信息。
d. 事务提交确认
协调者接收到所有参与者反馈的Ack信息后,完成事务。
中断事务过程如下:
a. 发送回滚请求
协调者向所有参与者发出Rollback请求。
b. 事务回滚
参与者接收到Rollback请求后,会利用其在提交阶段种记录的Undo信息,来执行事务回滚操作。在完成回滚之后,释放在整个事务执行期间占用的资源。
c. 反馈事务回滚结果
参与者在完成事务回滚之后,想协调者发送Ack信息。
d. 事务中断确认
协调者接收到所有参与者反馈的Ack信息后,完成事务中断。
3.1. 二阶段提交的优缺点
优点:原理简单,实现方便。
缺点:同步阻塞,单点问题,数据不一致,容错性不好。
同步阻塞
在二阶段提交的过程中,所有的节点都在等待其他节点的响应,无法进行其他操作。这种同步阻塞极大的限制了分布式系统的性能。
单点问题
协调者在整个二阶段提交过程中很重要,如果协调者在提交阶段出现问题,那么整个流程将无法运转。更重要的是,其他参与者将会处于一直锁定事务资源的状态中,而无法继续完成事务操作。
数据不一致
假设当协调者向所有的参与者发送commit请求之后,发生了局部网络异常,或者是协调者在尚未发送完所有 commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求。这将导致严重的数据不一致问题。
容错性不好
如果在二阶段提交的提交询问阶段中,参与者出现故障,导致协调者始终无法获取到所有参与者的确认信息,这时协调者只能依靠其自身的超时机制,判断是否需要中断事务。显然,这种策略过于保守。换句话说,二阶段提交协议没有设计较为完善的容错机制,任意一个节点是失败都会导致整个事务的失败。
对于2PC协议存在的同步阻塞、单点问题,将在下一篇文章的3PC协议中引入解决方案。
由于二阶段提交存在着诸如同步阻塞、单点问题、脑裂等缺陷。所以,研究者们在二阶段提交的基础上做了改进,提出了三阶段提交。
与两阶段提交不同的是,三阶段提交有两个改动点。
引入超时机制 - 同时在协调者和参与者中都引入超时机制。
在第一阶段和第二阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点的状态是一致的。
三阶段提交(Three-phase commit),也叫三阶段提交协议(Three-phase commit protocol),是二阶段提交(2PC)的改进版本。
所谓的三个阶段分别是:询问,然后再锁资源,最后真正提交。
第一阶段:CanCommit
第二阶段:PreCommit
第三阶段:Do Commit
2.1. 阶段一:CanCommit
3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
a. 事务询问
协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作。然后开始等待参与者的响应。
b. 响应反馈
参与者接到CanCommit请求之后,正常情况下,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态;否则反馈No。
2.2. 阶段二:PreCommit
协调者在得到所有参与者的响应之后,会根据结果执行2种操作:执行事务预提交,或者中断事务。
2.2.1. 执行事务预提交
a. 发送预提交请求
协调者向所有参与者节点发出 preCommit 的请求,并进入 prepared 状态。
b. 事务预提交
参与者受到 preCommit 请求后,会执行事务操作,对应 2PC 准备阶段中的 “执行事务”,也会 Undo 和 Redo 信息记录到事务日志中。
c. 各参与者响应反馈
如果参与者成功执行了事务,就反馈 ACK 响应,同时等待指令:提交(commit) 或终止(abort)。
2.2.2. 中断事务
a. 发送中断请求
协调者向所有参与者节点发出 abort 请求 。
b. 中断事务
参与者如果收到 abort 请求或者超时了,都会中断事务。
2.3. 阶段三:Do Commit
该阶段进行真正的事务提交,也可以分为以下两种情况。
2.3.1. 执行提交
a. 发送提交请求
协调者接收到各参与者发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有参与者发送 doCommit 请求。
b. 事务提交
参与者接收到 doCommit 请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
c. 响应反馈
事务提交完之后,向协调者发送 ACK 响应。
d. 完成事务
协调者接收到所有参与者的 ACK 响应之后,完成事务。
2.3.2. 中断事务
协调者没有接收到参与者发送的 ACK 响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
a. 发送中断请求
协调者向所有参与者发送 abort 请求。
b. 事务回滚
参与者接收到 abort 请求之后,利用其在阶段二记录的 undo 信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
c. 反馈结果
参与者完成事务回滚之后,向协调者发送 ACK 消息。
d. 中断事务
协调者接收到参与者反馈的 ACK 消息之后,完成事务的中断。
3.1. 三阶段提交的优点
相对于二阶段提交,三阶段提交主要解决的单点故障问题,并减少了阻塞的时间。
因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行 commit。而不会一直持有事务资源并处于阻塞状态。
3.2. 三阶段提交的缺点
三阶段提交也会导致数据一致性问题。由于网络原因,协调者发送的 abort 响应没有及时被参与者接收到,那么参与者在等待超时之后执行了 commit 操作。
这样就和其他接到 abort 命令并执行回滚的参与者之间存在数据不一致的情况。
用于达成共识性问题,即对多个节点产生的值,该算法能保证只选出唯一一个值。
主要有三类节点:
提议者(Proposer):提议一个值;
接受者(Acceptor):对每个提议进行投票;
告知者(Learner):被告知投票的结果,不参与投票过程。
执行过程
规定一个提议包含两个字段:[n, v],其中 n 为序号(具有唯一性),v 为提议值。
下图演示了两个 Proposer 和三个 Acceptor 的系统中运行该算法的初始过程,每个 Proposer 都会向所有 Acceptor 发送提议请求。
当 Acceptor 接收到一个提议请求,包含的提议为 [n1, v1],并且之前还未接收过提议请求,那么发送一个提议响应,设置当前接收到的提议为 [n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
如下图,Acceptor X 在收到 [n=2, v=8] 的提议请求时,由于之前没有接收过提议,因此就发送一个 [no previous] 的提议响应,设置当前接收到的提议为 [n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。
如果 Acceptor 接收到一个提议请求,包含的提议为 [n2, v2],并且之前已经接收过提议 [n1, v1]。如果 n1 > n2,那么就丢弃该提议请求;否则,发送提议响应,该提议响应包含之前已经接收过的提议 [n1, v1],设置当前接收到的提议为 [n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
如下图,Acceptor Z 收到 Proposer A 发来的 [n=2, v=8] 的提议请求,由于之前已经接收过 [n=4, v=5] 的提议,并且 n > 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 [n=4, v=5] 的提议请求,因为之前接收到的提议为 [n=2, v=8],并且 2 <= 4,因此就发送 [n=2, v=8] 的提议响应,设置当前接收到的提议为 [n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。
当一个 Proposer 接收到超过一半 Acceptor 的提议响应时,就可以发送接受请求。
Proposer A 接收到两个提议响应之后,就发送 [n=2, v=8] 接受请求。该接受请求会被所有 Acceptor 丢弃,因为此时所有 Acceptor 都保证不接受序号小于 4 的提议。
Proposer B 过后也收到了两个提议响应,因此也开始发送接受请求。需要注意的是,接受请求的 v 需要取它收到的大 v 值,也就是 8。因此它发送 [n=4, v=8] 的接受请求。
Acceptor 接收到接受请求时,如果序号大于等于该 Acceptor 承诺的最小序号,那么就发送通知给所有的 Learner。当 Learner 发现有大多数的 Acceptor 接收了某个提议,那么该提议的提议值就被 Paxos 选择出来。
约束条件
正确性
指只有一个提议值会生效。
因为 Paxos 协议要求每个生效的提议被多数 Acceptor 接收,并且 Acceptor 不会接受两个不同的提议,因此可以保证正确性。
可终止性
指最后总会有一个提议生效。
Paxos 协议能够让 Proposer 发送的提议朝着能被大多数 Acceptor 接受的那个提议靠拢,因此能够保证可终止性。
1 Paxos算法
1.1 基本定义
算法中的参与者主要分为三个角色,同时每个参与者又可兼领多个角色:
⑴proposer 提出提案,提案信息包括提案编号和提议的value;
⑵acceptor 收到提案后可以接受(accept)提案;
⑶learner 只能”学习”被批准的提案;
算法保重一致性的基本语义:
⑴决议(value)只有在被proposers提出后才能被批准(未经批准的决议称为”提案(proposal)”);
⑵在一次Paxos算法的执行实例中,只批准(chosen)一个value;
⑶learners只能获得被批准(chosen)的value;
有上面的三个语义可演化为四个约束:
⑴P1:一个acceptor必须接受(accept)第一次收到的提案;
⑵P2a:一旦一个具有value v的提案被批准(chosen),那么之后任何acceptor 再次接受(accept)的提案必须具有value v;
⑶P2b:一旦一个具有value v的提案被批准(chosen),那么以后任何 proposer 提出的提案必须具有value v;
⑷P2c:如果一个编号为n的提案具有value v,那么存在一个多数派,要么他们中所有人都没有接受(accept)编号小于n的任何提案,要么他们已经接受(accpet)的所有编号小于n的提案中编号大的那个提案具有value v;
1.2 基本算法(basic paxos)
算法(决议的提出与批准)主要分为两个阶段:
prepare阶段:
(1). 当Porposer希望提出方案V1,首先发出prepare请求至大多数Acceptor。Prepare请求内容为序列号
(2). 当Acceptor接收到prepare请求
a). 如果SN2>SN1,则忽略此请求,直接结束本次批准过程;
b). 否则检查上次批准的accept请求
accept批准阶段:
(1a). 经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
a). 回复数量满足多数派,并且所有的回复都是
b). 回复数量满足多数派,但有的回复为:
c). 回复数量不满足多数派,Proposer尝试增加序列号为SN1+,转1继续执行;
(1b). 经过一段时间,收到一些Acceptor回复,回复可分为以下几种:
a). 回复数量满足多数派,则确认V1被接受;
b). 回复数量不满足多数派,V1未被接受,Proposer增加序列号为SN1+,转1继续执行;
(2). 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept 请求后即接受并回复这个请求。
1.3 算法优化(fast paxos)
Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。因此,为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。
在这种优化算法中,只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致,此时的paxos算法在本质上就退变为两阶段提交协议。但在异常情况下,系统可能会出现多Leader的情况,但这并不会破坏算法对一致性的保证,此时多个Leader都可以提出自己的提案,优化的算法就退化成了原始的paxos算法。
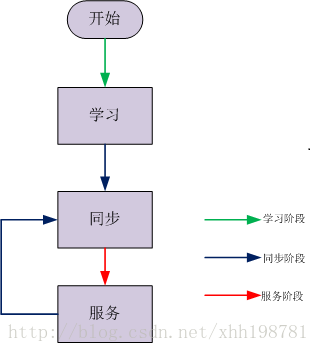
一个Leader的工作流程主要有分为三个阶段:
(1).学习阶段 向其它的参与者学习自己不知道的数据(决议);
(2).同步阶段 让绝大多数参与者保持数据(决议)的一致性;
(3).服务阶段 为客户端服务,提议案;
1.3.1 学习阶段
当一个参与者成为了Leader之后,它应该需要知道绝大多数的paxos实例,因此就会马上启动一个主动学习的过程。假设当前的新Leader早就知道了1-134、138和139的paxos实例,那么它会执行135-137和大于139的paxos实例的第一阶段。如果只检测到135和140的paxos实例有确定的值,那它最后就会知道1-135以及138-140的paxos实例。
1.3.2 同步阶段
此时的Leader已经知道了1-135、138-140的paxos实例,那么它就会重新执行1-135的paxos实例,以保证绝大多数参与者在1-135的paxos实例上是保持一致的。至于139-140的paxos实例,它并不马上执行138-140的paxos实例,而是等到在服务阶段填充了136、137的paxos实例之后再执行。这里之所以要填充间隔,是为了避免以后的Leader总是要学习这些间隔中的paxos实例,而这些paxos实例又没有对应的确定值。
1.3.4 服务阶段
Leader将用户的请求转化为对应的paxos实例,当然,它可以并发的执行多个paxos实例,当这个Leader出现异常之后,就很有可能造成paxos实例出现间断。
1.3.5 问题
(1).Leader的选举原则
(2).Acceptor如何感知当前Leader的失败,客户如何知道当前的Leader
(3).当出现多Leader之后,如何kill掉多余的Leader
(4).如何动态的扩展Acceptor
Raft 和 Paxos 类似,但是更容易理解,也更容易实现。
Raft 主要是用来竞选主节点。
单个 Candidate 的竞选
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
下图表示一个分布式系统的最初阶段,此时只有 Follower,没有 Leader。Follower A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
此时 A 发送投票请求给其它所有节点。
其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
多个 Candidate 竞选
如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票,例如下图中 Candidate B 和 Candidate D 都获得两票,因此需要重新开始投票。
当重新开始投票时,由于每个节点设置的随机竞选超时时间不同,因此能下一次再次出现多个 Candidate 并获得同样票数的概率很低。
日志复制
来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
Leader 会把修改复制到所有 Follower。
Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
感谢各位的阅读,以上就是“Java分布式一致性协议与Paxos,Raft算法是什么”的内容了,经过本文的学习后,相信大家对Java分布式一致性协议与Paxos,Raft算法是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!